
Owing to a rise in pure and artificial speech synthesis approaches, one of many main achievements the AI trade has achieved previously few years is to successfully synthesize text-to-speech frameworks with potential purposes throughout totally different industries together with audiobooks, digital assistants, voice-over narrations and extra, with some cutting-edge modes delivering human-level efficiency and effectivity throughout a big selection of speech-related duties. Nonetheless, regardless of their sturdy efficiency, there’s nonetheless room for enchancment for duties because of expressive & various speech, requirement for a considerable amount of coaching knowledge for optimizing zero-shot textual content to speech frameworks, and robustness for OOD or Out of Distribution texts main builders to work on a extra sturdy and accessible textual content to speech framework.
On this article, we might be speaking about StyleTTS-2, a sturdy and modern textual content to speech framework that’s constructed on the foundations of the StyleTTS framework, and goals to current the subsequent step in the direction of cutting-edge textual content to speech methods. The StyleTTS2 framework fashions speech kinds as latent random variables, and makes use of a probabilistic diffusion mannequin to pattern these speech kinds or random variables thus permitting the StyleTTS2 framework to synthesize reasonable speech successfully with out utilizing reference audio inputs. Owing to the method, the StyleTTS2 framework is ready to ship higher outcomes & exhibits excessive effectivity when in comparison with present cutting-edge textual content to speech frameworks, however can be capable of benefit from the various speech synthesis supplied by diffusion mannequin frameworks. We might be discussing the StyleTTS2 framework in better element, and speak about its structure and methodology whereas additionally taking a look on the outcomes achieved by the framework. So let’s get began.
StyleTTS2 is an modern Textual content to Speech synthesis mannequin that takes the subsequent step in the direction of constructing human-level TTS frameworks, and it’s constructed upon StyleTTS, a style-based textual content to speech generative mannequin. The StyleTTS2 framework fashions speech kinds as latent random variables, and makes use of a probabilistic diffusion mannequin to pattern these speech kinds or random variables thus permitting the StyleTTS2 framework to synthesize reasonable speech successfully with out utilizing reference audio inputs. Modeling kinds as latent random variables is what separates the StyleTTS2 framework from its predecessor, the StyleTTS framework, and goals to generate essentially the most appropriate speech fashion for the enter textual content without having a reference audio enter, and is ready to obtain efficient latent diffusions whereas making the most of the various speech synthesis capabilities supplied by diffusion fashions. Moreover, the StyleTTS2 framework additionally employs pre-trained giant SLM or Speech Language Mannequin as discriminators just like the WavLM framework, and {couples} it with its personal novel differential period modeling method to coach the framework finish to finish, and in the end producing speech with enhanced naturalness. Due to the method it follows, the StyleTTS2 framework outperforms present cutting-edge frameworks for speech era duties, and is without doubt one of the most effective frameworks for pre-training large-scale speech fashions in zero-shot setting for speaker adaptation duties.
Shifting alongside, to ship human-level textual content to speech synthesis, the StyleTTs2 framework incorporates the learnings from current works together with diffusion fashions for speech synthesis, and huge speech language fashions. Diffusion fashions are normally used for speech synthesis duties because of their talents to fine-grain speech management, and various speech sampling capabilities. Nonetheless, diffusion fashions will not be as environment friendly as GAN-based non-iterative frameworks and a serious purpose for that is the requirement to pattern latent representations, waveforms, and mel-spectrograms iteratively to the goal period of the speech.
However, latest works round Massive Speech Language Fashions have indicated their capacity to reinforce the standard of textual content to speech era duties, and adapt nicely to the speaker. Massive Speech Language Fashions usually convert textual content enter both into quantized or steady representations derived from pre-trained speech language frameworks for speech reconstructing duties. Nonetheless, the options of those Speech Language Fashions will not be optimized for speech synthesis instantly. In distinction, the StyleTTS2 framework takes benefit of the information gained by giant SLM frameworks utilizing adversarial coaching to synthesize speech language fashions’ options with out utilizing latent house maps, and due to this fact, studying a speech synthesis optimized latent house instantly.
StyleTTS2: Structure and Methodology
At its core, the StyleTTS2 is constructed on its predecessor, the StyleTTS framework which is a non-autoregressive textual content to speech framework that makes use of a method encoder to derive a method vector from the reference audio, thus permitting expressive and pure speech era. The fashion vector used within the StyleTTS framework is included instantly into the encoder, period, and predictors by making use of AdaIN or Adaptive Occasion Normalization, thus permitting the StyleTTS mannequin to generate speech outputs with various prosody, period, and even feelings. The StyleTTS framework consists of 8 fashions in whole which can be divided into three classes
- Acoustic Fashions or Speech Technology System with a method encoder, a textual content encoder, and a speech decoder.
- A Textual content to Speech Prediction System making use of prosody and period predictors.
- A Utility System together with a textual content aligner, a pitch extractor, and a discriminator for coaching functions.
Due to its method, the StyleTTS framework delivers cutting-edge efficiency associated to controllable and various speech synthesis. Nonetheless, this efficiency has its drawbacks like degradation of pattern high quality, expressive limitations, and reliance on speech-hindering purposes in real-time.
Bettering upon the StyleTTS framework, the StyleTTS2 mannequin ends in enhanced expressive textual content to speech duties with an improved out of distribution efficiency, and a excessive human-level high quality. The StyleTTS2 framework makes use of an finish to finish coaching course of that optimizes the totally different parts with adversarial coaching, and direct waveform synthesis collectively. Not like the StyleTTS framework, the StyleTTS2 framework fashions the speech fashion as a latent variable, and samples it through diffusion fashions thus producing various speech samples with out utilizing a reference audio. Let’s have an in depth look into these parts.
Finish to Finish Coaching for Interference
Within the StyleTTS2 framework, an finish to finish coaching method is utilized to optimize varied textual content to speech parts for interference with out having to depend on mounted parts. The StyleTTS2 framework achieves this by modifying the decoder to generate the waveform instantly from the fashion vector, pitch & vitality curves, and aligned representations. The framework then removes the final projection layer of the decoder, and replaces it with a waveform decoder. The StyleTTS2 framework makes use of two encoders: HifiGAN-based decoder to generate the waveform instantly, and an iSTFT-based decoder to provide section & magnitude which can be transformed into waveforms for quicker interference & coaching.
The above determine represents the acoustic fashions used for pre-training and joint coaching. To cut back the coaching time, the modules are first optimized within the pre-training section adopted by the optimization of all of the parts minus the pitch extractor throughout joint coaching. The rationale why joint coaching doesn’t optimize the pitch extractor is as a result of it’s used to offer the bottom reality for pitch curves.

The above determine represents the Speech Language Mannequin adversarial coaching and interference with the WavLM framework pre-trained however not pre-tuned. The method differs from the one talked about above as it may possibly take various enter texts however accumulates the gradients to replace the parameters in every batch.
Fashion Diffusion
The StyleTTS2 framework goals to mannequin speech as a conditional distribution by means of a latent variable that follows the conditional distribution, and this variable is named the generalized speech fashion, and represents any attribute within the speech pattern past the scope of any phonetic content material together with lexical stress, prosody, talking charge, and even formant transitions.
Speech Language Mannequin Discriminators
Speech Language Fashions are famend for his or her basic talents to encode invaluable data on a variety of semantics and acoustic facets, and SLM representations have historically been capable of mimic human perceptions to judge the standard of the generated synthesized speech. The StyleTTS2 framework makes use of an adversarial coaching method to make the most of the power of SLM encoders to carry out generative duties, and employs a 12-layer WavLM framework because the discriminator. This method permits the framework to allow coaching on OOD or Out Of Distribution texts that may assist enhance efficiency. Moreover, to forestall overfitting points, the framework samples OOD texts and in-distribution with equal likelihood.
Differentiable Period Modeling
Historically, a period predictor is utilized in textual content to speech frameworks that produces phoneme durations, however the upsampling strategies these period predictors use usually block the gradient circulation through the E2E coaching course of, and the NaturalSpeech framework employs an attention-based upsampler for human-level textual content to speech conversion. Nonetheless, the StyleTTS2 framework finds this method to be unstable throughout adversarial coaching as a result of the StyleTTS2 trains utilizing differentiable upsampling with totally different adversarial coaching with out the lack of additional phrases attributable to mismatch within the size attributable to deviations. Though utilizing a tender dynamic time warping method may also help in mitigating this mismatch, utilizing it’s not solely computationally costly, however its stability can be a priority when working with adversarial goals or mel-reconstruction duties. Due to this fact, to realize human-level efficiency with adversarial coaching and stabilize the coaching course of, the StyleTTC2 framework makes use of a non-parametric upsampling method. Gaussian upsampling is a well-liked nonparametric upsampling method for changing the expected durations though it has its limitations because of the mounted size of the Gaussian kernels predetermined. This restriction for Gaussian upsampling limits its capacity to precisely mannequin alignments with totally different lengths.
To come across this limitation, the StyleTTC2 framework proposes to make use of a brand new nonparametric upsampling method with none further coaching, and able to accounting various lengths of the alignments. For every phoneme, the StyleTTC2 framework fashions the alignment as a random variable, and signifies the index of the speech body with which the phoneme aligns with.
Mannequin Coaching and Analysis
The StyleTTC2 framework is educated and experimented on three datasets: VCTK, LibriTTS, and LJSpeech. The only-speaker part of the StyleTTS2 framework is educated utilizing the LJSpeech dataset that incorporates roughly 13,000+ audio samples break up into 12,500 coaching samples, 100 validation samples, and almost 500 testing samples, with their mixed run time totalling to almost 24 hours. The multi speaker part of the framework is educated on the VCTK dataset consisting of over 44,000 audio clips with over 100 particular person native audio system with various accents, and is break up into 43,500 coaching samples, 100 validation samples, and almost 500 testing samples. Lastly, to equip the framework with zero-shot adaptation capabilities, the framework is educated on the mixed LibriTTS dataset that consists of audio clips totaling to about 250 hours of audio with over 1,150 particular person audio system. To guage its efficiency, the mannequin employs two metrics: MOS-N or Imply Opinion Rating of Naturalness, and MOS-S or Imply Opinion Rating of Similarity.

Outcomes
The method and methodology used within the StyleTTS2 framework is showcased in its efficiency because the mannequin outperforms a number of cutting-edge TTS frameworks particularly on the NaturalSpeech dataset, and enroute, setting a brand new customary for the dataset. Moreover, the StyleTTS2 framework outperforms the cutting-edge VITS framework on the VCTK dataset, and the outcomes are demonstrated within the following determine.

The StyleTTS2 mannequin additionally outperforms earlier fashions on the LJSpeech dataset, and it doesn’t show any diploma of high quality degradation on OOD or Out of Distribution texts as displayed by prior frameworks on the identical metrics. Moreover, in zero-shot setting, the StyleTTC2 mannequin outperforms the prevailing Vall-E framework in naturalness though it falls behind when it comes to similarity. Nonetheless, it’s value noting that the StyleTTS2 framework is ready to obtain aggressive efficiency regardless of coaching solely on 245 hours of audio samples when in comparison with over 60k hours of coaching for the Vall-E framework, thus proving StyleTTC2 to be a data-efficient various to current giant pre-training strategies as used within the Vall-E.

Shifting alongside, owing to the shortage of emotion labeled audio textual content knowledge, the StyleTTC2 framework makes use of the GPT-4 mannequin to generate over 500 cases throughout totally different feelings for the visualization of favor vectors the framework creates utilizing its diffusion course of.

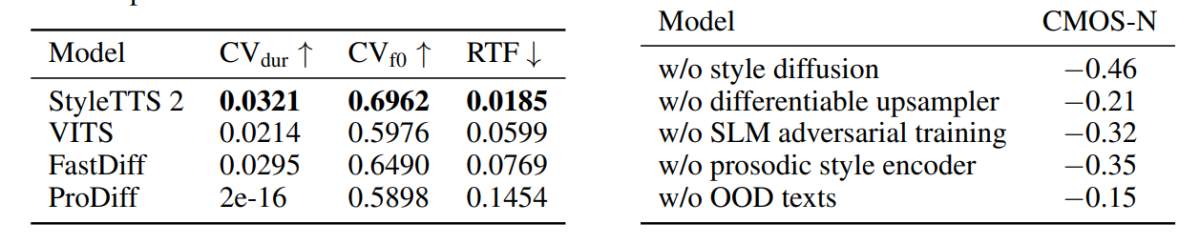
Within the first determine, emotional kinds in response to enter textual content sentiments are illustrated by the fashion vectors from the LJSpeech mannequin, and it demonstrates the power of the StyleTTC2 framework to synthesize expressive speech with diversified feelings. The second determine depicts distinct clusters type for every of the 5 particular person audio system thus depicting a variety of range sourced from a single audio file. The ultimate determine demonstrates the unfastened cluster of feelings from speaker 1, and divulges that, regardless of some overlaps, emotion-based clusters are outstanding, thus indicating the potential for manipulating the emotional tune of a speaker whatever the reference audio pattern and its enter tone. Regardless of utilizing a diffusion based mostly method, the StyleTTS2 framework manages to outperform current cutting-edge frameworks together with VITS, ProDiff, and FastDiff.
Last Ideas
On this article, we have now talked about StyleTTS2, a novel, sturdy and modern textual content to speech framework that’s constructed on the foundations of the StyleTTS framework, and goals to current the subsequent step in the direction of cutting-edge textual content to speech methods. The StyleTTS2 framework fashions speech kinds as latent random variables, and makes use of a probabilistic diffusion mannequin to pattern these speech kinds or random variables thus permitting the StyleTTS2 framework to synthesize reasonable speech successfully with out utilizing reference audio inputs.The StyleTTS2 framework makes use of fashion diffusion and SLM discriminators to realize human-level efficiency on textual content to speech duties, and manages to outperform current cutting-edge frameworks on a big selection of speech duties.

