
As a consequence of its huge potential and commercialization alternatives, notably in gaming, broadcasting, and video streaming, the Metaverse is at the moment one of many fastest-growing applied sciences. Trendy Metaverse purposes make the most of AI frameworks, together with laptop imaginative and prescient and diffusion fashions, to reinforce their realism. A big problem for Metaverse purposes is integrating varied diffusion pipelines that present low latency and excessive throughput, guaranteeing efficient interplay between people and these purposes.
In the present day’s diffusion-based AI frameworks excel in creating pictures from textual or picture prompts however fall brief in real-time interactions. This limitation is especially evident in duties that require steady enter and excessive throughput, resembling online game graphics, Metaverse purposes, broadcasting, and dwell video streaming.
On this article, we are going to focus on StreamDiffusion, a real-time diffusion pipeline developed to generate interactive and reasonable pictures, addressing the present limitations of diffusion-based frameworks in duties involving steady enter. StreamDiffusion is an progressive strategy that transforms the sequential noising of the unique picture into batch denoising, aiming to allow excessive throughput and fluid streams. This strategy strikes away from the normal wait-and-interact technique utilized by present diffusion-based frameworks. Within the upcoming sections, we are going to delve into the StreamDiffusion framework intimately, exploring its working, structure, and comparative outcomes towards present state-of-the-art frameworks. Let’s get began.
Metaverse are efficiency intensive purposes as they course of a considerable amount of knowledge together with texts, animations, movies, and pictures in real-time to supply its customers with its trademark interactive interfaces and expertise. Trendy Metaverse purposes depend on AI-based frameworks together with laptop imaginative and prescient, picture processing, and diffusion fashions to achieve low latency and a excessive throughput to make sure a seamless consumer expertise. At the moment, a majority of Metaverse purposes depend on lowering the prevalence of denoising iterations to make sure excessive throughput and improve the appliance’s interactive capabilities in real-time. These frameworks go for a typical technique that both entails re-framing the diffusion course of with neural ODEs (Peculiar Differential Equations) or lowering multi-step diffusion fashions into a couple of steps or perhaps a single step. Though the strategy delivers passable outcomes, it has sure limitations together with restricted flexibility, and excessive computational prices.
Then again, the StreamDiffusion is a pipeline stage resolution that begins from an orthogonal course and enhances the framework’s capabilities to generate interactive pictures in real-time whereas guaranteeing a excessive throughput. StreamDiffusion makes use of a easy technique during which as an alternative of denoising the unique enter, the framework batches the denoising step. The technique takes inspiration from asynchronous processing because the framework doesn’t have to attend for the primary denoising stage to finish earlier than it might probably transfer on to the second stage, as demonstrated within the following picture. To deal with the problem of U-Internet processing frequency and enter frequency synchronously, the StreamDiffusion framework implements a queue technique to cache the enter and the outputs.
Though the StreamDiffusion pipeline seeks inspiration from asynchronous processing, it’s distinctive in its personal manner because it implements GPU parallelism that enables the framework to make the most of a single UNet part to denoise a batched noise latent characteristic. Moreover, present diffusion-based pipelines emphasize on the given prompts within the generated pictures by incorporating classifier-free steering, because of which the present pipelines are rigged with redundant and extreme computational overheads. To make sure the StreamDiffusion pipeline don’t encounter the identical points, it implements an progressive RCFG or Residual Classifier-Free Steerage strategy that makes use of a digital residual noise to approximate the damaging circumstances, thus permitting the framework to calculate the damaging noise circumstances within the preliminary levels of the method itself. Moreover, the StreamDiffusion pipeline additionally reduces the computational necessities of a standard diffusion-pipeline by implementing a stochastic similarity filtering technique that determines whether or not the pipeline ought to course of the enter pictures by computing the similarities between steady inputs.
The StreamDiffusion framework is constructed on the learnings of diffusion fashions, and acceleration diffusion fashions.
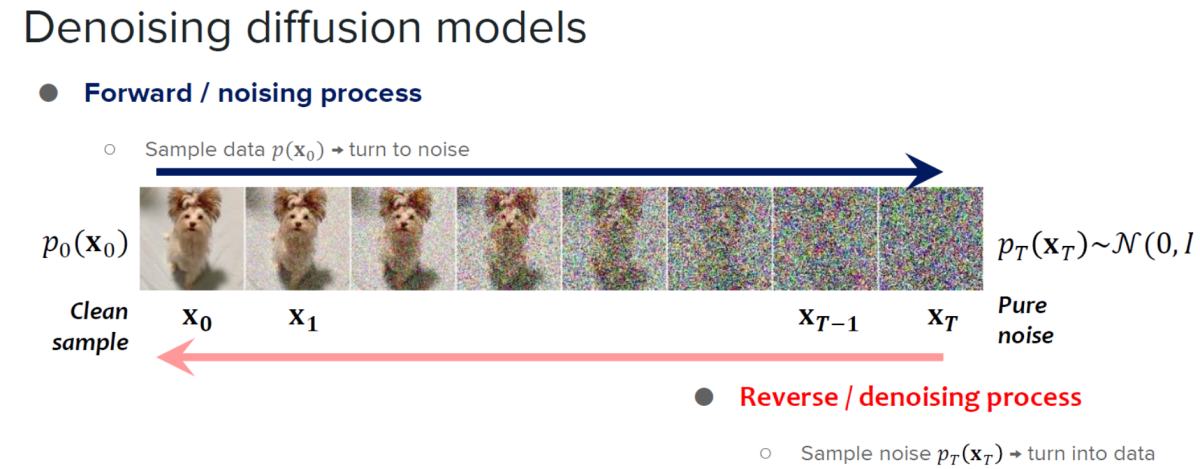
Diffusion fashions are identified for his or her distinctive picture technology capabilities and the quantity of management they provide. Owing to their capabilities, diffusion fashions have discovered their purposes in picture modifying, textual content to picture technology, and video technology. Moreover, growth of constant fashions have demonstrated the potential to reinforce the pattern processing effectivity with out compromising on the standard of the pictures generated by the mannequin that has opened new doorways to develop the applicability and effectivity of diffusion fashions by lowering the variety of sampling steps. Though extraordinarily succesful, diffusion fashions are likely to have a significant limitation: sluggish picture technology. To deal with this limitation, builders launched accelerated diffusion fashions, diffusion-based frameworks that don’t require extra coaching steps or implement predictor-corrector methods and adaptive step-size solvers to extend the output speeds.
The distinguishing issue between StreamDiffusion and conventional diffusion-based frameworks is that whereas the latter focuses totally on low latency of particular person fashions, the previous introduces a pipeline-level strategy designed for attaining excessive throughputs enabling environment friendly interactive diffusion.
StreamDiffusion : Working and Structure
The StreamDiffusion pipeline is a real-time diffusion pipeline developed for producing interactive and reasonable pictures, and it employs 6 key elements specifically: RCFG or Residual Classifier Free Steerage, Stream Batch technique, Stochastic Similarity Filter, an input-output queue, mannequin acceleration instruments with autoencoder, and a pre-computation process. Let’s discuss these elements intimately.
Stream Batch Technique
Historically, the denoising steps in a diffusion mannequin are carried out sequentially, leading to a major improve within the U-Internet processing time to the variety of processing steps. Nonetheless, it’s important to extend the variety of processing steps to generate high-fidelity pictures, and the StreamDiffusion framework introduces the Stream Batch technique to beat high-latency decision in interactive diffusion frameworks.
Within the Stream Batch technique, the sequential denoising operations are restructured into batched processes with every batch akin to a predetermined variety of denoising steps, and the variety of these denoising steps is decided by the dimensions of every batch. Due to the strategy, every aspect within the batch can proceed one step additional utilizing the one passthrough UNet within the denoising sequence. By implementing the stream batch technique iteratively, the enter pictures encoded at timestep “t” could be reworked into their respective picture to picture outcomes at timestep “t+n”, thus streamlining the denoising course of.
Residual Classifier Free Steerage
CFG or Classifier Free Steerage is an AI algorithm that performs a number of vector calculations between the unique conditioning time period and a damaging conditioning or unconditioning time period to reinforce the impact of authentic conditioning. The algorithm strengthens the impact of the immediate regardless that to compute the damaging conditioning residual noise, it’s essential to pair particular person enter latent variables with damaging conditioning embedding adopted up by passing the embeddings via the UNet at reference time.
To deal with this problem posed by Classifier Free Steerage algorithm, the StreamDiffusion framework introduces Residual Classifier Free Steerage algorithm with the goal to scale back computational prices for extra UNet interference for damaging conditioning embedding. First, the encoded latent enter is transferred to the noise distribution by utilizing values decided by the noise scheduler. As soon as the latent consistency mannequin has been applied, the algorithm can predict knowledge distribution, and use the CFG residual noise to generate the following step noise distribution.
Enter Output Queue
The main problem with high-speed picture technology frameworks is their neural community modules together with the UNet and VAE elements. To maximise the effectivity and total output velocity, picture technology frameworks transfer processes like pre and submit processing pictures that don’t require extra dealing with by the neural community modules outdoors of the pipeline, submit which they’re processed in parallel. Moreover, by way of dealing with the enter picture, particular operations together with conversion of tensor format, resizing enter pictures, and normalization are executed by the pipeline meticulously.
To deal with the disparity in processing frequencies between the mannequin throughput and the human enter, the pipeline integrates an input-output queuing system that permits environment friendly parallelization as demonstrated within the following picture.
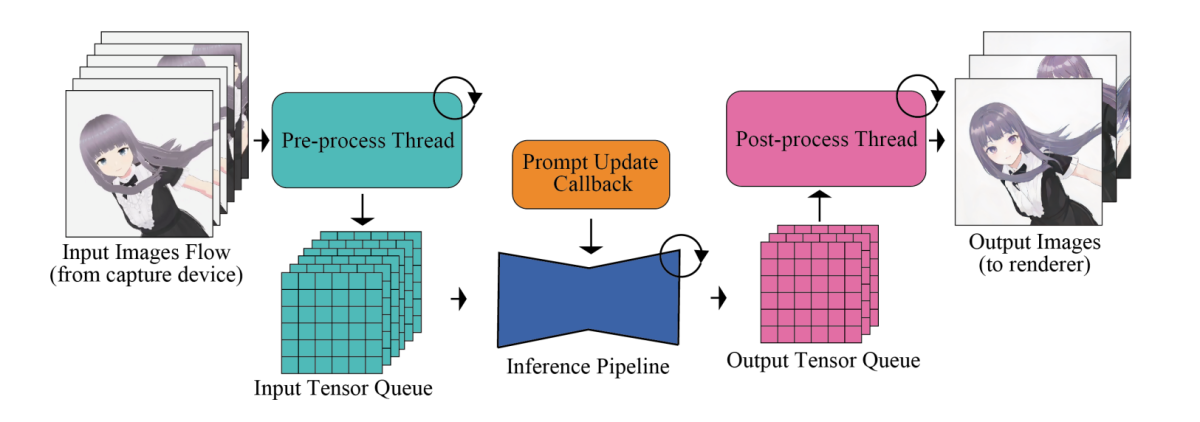
The processed enter tensors are first queued methodically for Diffusion fashions, and through every body, the mannequin retrieves the latest tensor from the enter queue, and forwards the tensor to the VAE encoder, thus initiating the picture technology course of. On the identical time, the tensor output from the VAE decoder is fed into the output queue. Lastly, the processed picture knowledge is transmitted to the rendering consumer.
Stochastic Similarity Filter
In situations the place the pictures both stay unchanged or present minimal modifications with no static setting or with out lively consumer interplay, enter pictures resembling one another are fed repeatedly into UNet and VAE elements. The repeated feeding results in technology of close to an identical pictures and extra consumption of GPU sources. Moreover, in situations involving steady inputs, unmodified enter pictures may floor often. To beat this problem and stop pointless utilization of sources, the StreamDiffusion pipeline employs a Stochastic Similarity Filter part in its pipeline. The Stochastic Similarity Filter first calculates the cosine similarity between the reference picture and the enter picture, and makes use of the cosine similarity rating to calculate the chance of skipping the next UNet and VAE processes.
On the premise of the chance rating, the pipeline decides whether or not subsequent processes like VAE Encoding, VAE Decoding, and U-Internet must be skipped or not. If these processes should not skipped, the pipeline saves the enter picture at the moment, and concurrently updates the reference picture for use sooner or later. This probability-based skipping mechanism permits the StreamDiffusion pipeline to completely function in dynamic situations with low inter-frame similarity whereas in static situations, the pipeline operates with larger inter-frame similarity. The strategy helps in conserving the computational sources and likewise ensures optimum GPU utilization primarily based on the similarity of the enter pictures.
Pre-Computation
The UNet structure wants each conditioning embeddings in addition to enter latent variables. Historically, the conditioning embeddings are derived from immediate embeddings that stay fixed throughout frames. To optimize the derivation from immediate embeddings, the StreamDiffusion pipeline pre-computed these immediate embeddings and shops them in a cache, that are then known as in streaming or interactive mode. Throughout the UNet framework, the Key-Worth pair is computed on the premise of every body’s pre-computed immediate embedding, and with slight modifications within the U-Internet, these Key-Worth pairs could be reused.
Mannequin Acceleration and Tiny AutoEncoder
The StreamDiffusion pipeline employs TensorRT, an optimization toolkit from Nvidia for deep studying interfaces, to assemble the VAE and UNet engines, to speed up the inference velocity. To realize this, the TensorRT part performs quite a few optimizations on neural networks which might be designed to spice up effectivity and improve throughput for deep studying frameworks and purposes.
To optimize velocity, the StreamDiffusion configures the framework to make use of mounted enter dimensions and static batch sizes to make sure optimum reminiscence allocation and computational graphs for a particular enter dimension in an try to attain quicker processing occasions.
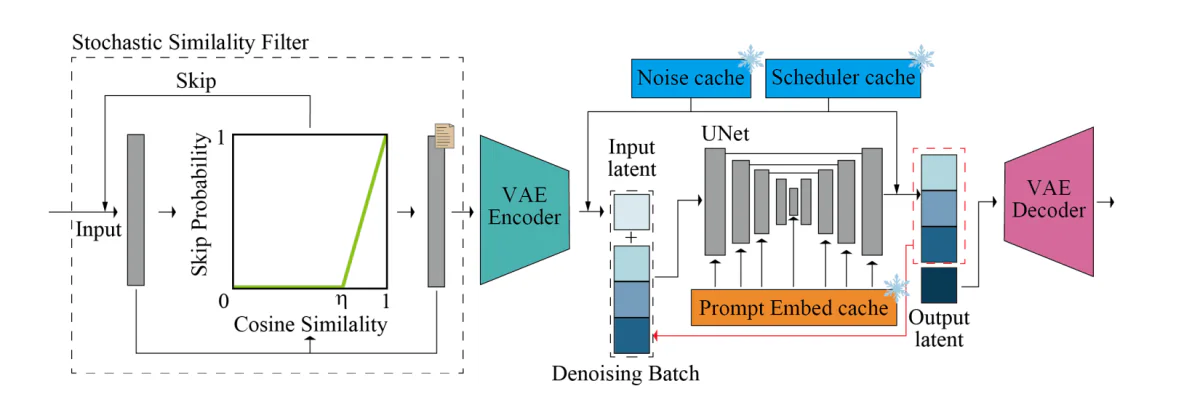
The above determine offers an outline of the inference pipeline. The core diffusion pipeline homes the UNet and VAE elements. The pipeline incorporates a denoising batch, sampled noise cache, pre-computed immediate embedding cache, and scheduler values cache to reinforce the velocity, and the power of the pipeline to generate pictures in real-time. The Stochastic Similarity Filter or SSF is deployed to optimize GPU utilization, and likewise to gate the move of the diffusion mannequin dynamically.
StreamDiffusion : Experiments and Outcomes
To guage its capabilities, the StreamDiffusion pipeline is applied on LCM and SD-turbo frameworks. The TensorRT by NVIDIA is used because the mannequin accelerator, and to allow light-weight effectivity VAE, the pipeline employs the TAESD part. Let’s now take a look at how the StreamDiffusion pipeline performs compared towards present cutting-edge frameworks.
Quantitative Analysis
The next determine demonstrates the effectivity comparability between the unique sequential UNet and the denoising batch elements within the pipeline, and as it may be seen, implementing the denoising batch strategy helps in lowering the processing time considerably by virtually 50% when in comparison with the normal UNet loops at sequential denoising steps.
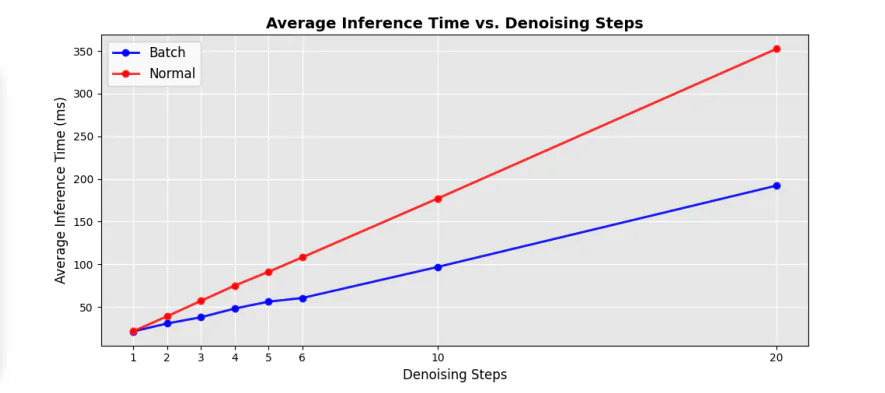
Moreover, the common inference time at totally different denoising steps additionally witnesses a considerable increase with totally different speedup elements compared towards present cutting-edge pipelines, and the outcomes are demonstrated within the following picture.

Transferring alongside, the StreamDiffusion pipeline with the RCFG part demonstrates much less inference time compared towards pipelines together with the normal CFG part.
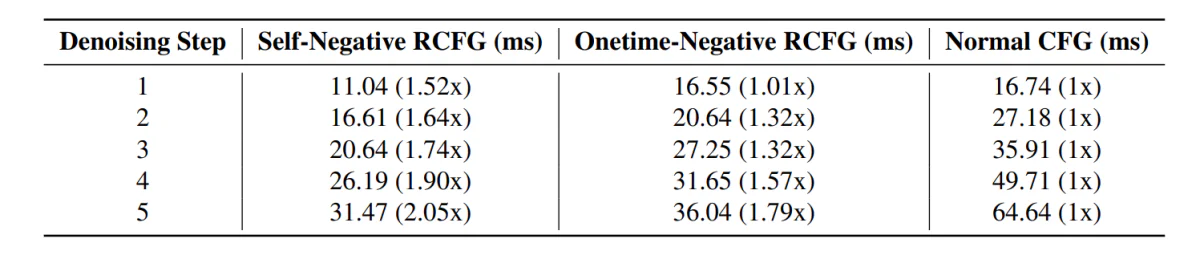
Moreover, the impression of utilizing the RCFG part its evident within the following pictures when in comparison with utilizing the CFG part.

As it may be seen, using CFG intesifies the impression of the textual immediate in picture technology, and the picture resembles the enter prompts much more when in comparison with the pictures generated by the pipeline with out utilizing the CFG part. The outcomes enhance additional with using the RCFG part because the affect of the prompts on the generated pictures is sort of vital when in comparison with the unique CFG part.
Last Ideas
On this article, we’ve got talked about StreamDiffusion, a real-time diffusion pipeline developed for producing interactive and reasonable pictures, and deal with the present limitations posed by diffusion-based frameworks on duties involving steady enter. StreamDiffusion is a straightforward and novel strategy that goals to remodel the sequential noising of the unique picture into batch denoising. StreamDiffusion goals to allow excessive throughput and fluid streams by eliminating the normal wait and work together strategy opted by present diffusion-based frameworks. The potential effectivity good points highlights the potential of StreamDiffusion pipeline for industrial purposes providing high-performance computing and compelling options for generative AI.

