
The combination and software of huge language fashions (LLMs) in medication and healthcare has been a subject of great curiosity and improvement.
As famous within the Healthcare Info Administration and Methods Society world convention and different notable occasions, firms like Google are main the cost in exploring the potential of generative AI inside healthcare. Their initiatives, corresponding to Med-PaLM 2, spotlight the evolving panorama of AI-driven healthcare options, significantly in areas like diagnostics, affected person care, and administrative effectivity.
Google’s Med-PaLM 2, a pioneering LLM within the healthcare area, has demonstrated spectacular capabilities, notably attaining an “skilled” degree in U.S. Medical Licensing Examination-style questions. This mannequin, and others prefer it, promise to revolutionize the way in which healthcare professionals entry and make the most of data, doubtlessly enhancing diagnostic accuracy and affected person care effectivity.
Nevertheless, alongside these developments, issues concerning the practicality and security of those applied sciences in scientific settings have been raised. For example, the reliance on huge web knowledge sources for mannequin coaching, whereas useful in some contexts, might not at all times be acceptable or dependable for medical functions. As Nigam Shah, PhD, MBBS, Chief Knowledge Scientist for Stanford Well being Care, factors out, the essential inquiries to ask are concerning the efficiency of those fashions in real-world medical settings and their precise impression on affected person care and healthcare effectivity.
Dr. Shah’s perspective underscores the necessity for a extra tailor-made strategy to using LLMs in medication. As an alternative of general-purpose fashions skilled on broad web knowledge, he suggests a extra targeted technique the place fashions are skilled on particular, related medical knowledge. This strategy resembles coaching a medical intern – offering them with particular duties, supervising their efficiency, and steadily permitting for extra autonomy as they reveal competence.
According to this, the event of Meditron by EPFL researchers presents an fascinating development within the subject. Meditron, an open-source LLM particularly tailor-made for medical purposes, represents a major step ahead. Educated on curated medical knowledge from respected sources like PubMed and scientific pointers, Meditron provides a extra targeted and doubtlessly extra dependable device for medical practitioners. Its open-source nature not solely promotes transparency and collaboration but additionally permits for steady enchancment and stress testing by the broader analysis group.
MEDITRON-70B-achieves-an-accuracy-of-70.2-on-USMLE-style-questions-in-the-MedQA-4-options-dataset
The event of instruments like Meditron, Med-PaLM 2, and others displays a rising recognition of the distinctive necessities of the healthcare sector on the subject of AI purposes. The emphasis on coaching these fashions on related, high-quality medical knowledge, and guaranteeing their security and reliability in scientific settings, could be very essential.
Furthermore, the inclusion of various datasets, corresponding to these from humanitarian contexts just like the Worldwide Committee of the Purple Cross, demonstrates a sensitivity to the numerous wants and challenges in world healthcare. This strategy aligns with the broader mission of many AI analysis facilities, which intention to create AI instruments that aren’t solely technologically superior but additionally socially accountable and useful.
The paper titled “Giant language fashions encode scientific data” just lately printed in Nature, explores how massive language fashions (LLMs) might be successfully utilized in scientific settings. The analysis presents groundbreaking insights and methodologies, shedding mild on the capabilities and limitations of LLMs within the medical area.
The medical area is characterised by its complexity, with an enormous array of signs, ailments, and coverings which might be continuously evolving. LLMs should not solely perceive this complexity but additionally sustain with the newest medical data and pointers.
The core of this analysis revolves round a newly curated benchmark known as MultiMedQA. This benchmark amalgamates six current medical question-answering datasets with a brand new dataset, HealthSearchQA, which includes medical questions regularly searched on-line. This complete strategy goals to guage LLMs throughout numerous dimensions, together with factuality, comprehension, reasoning, attainable hurt, and bias, thereby addressing the restrictions of earlier automated evaluations that relied on restricted benchmarks.
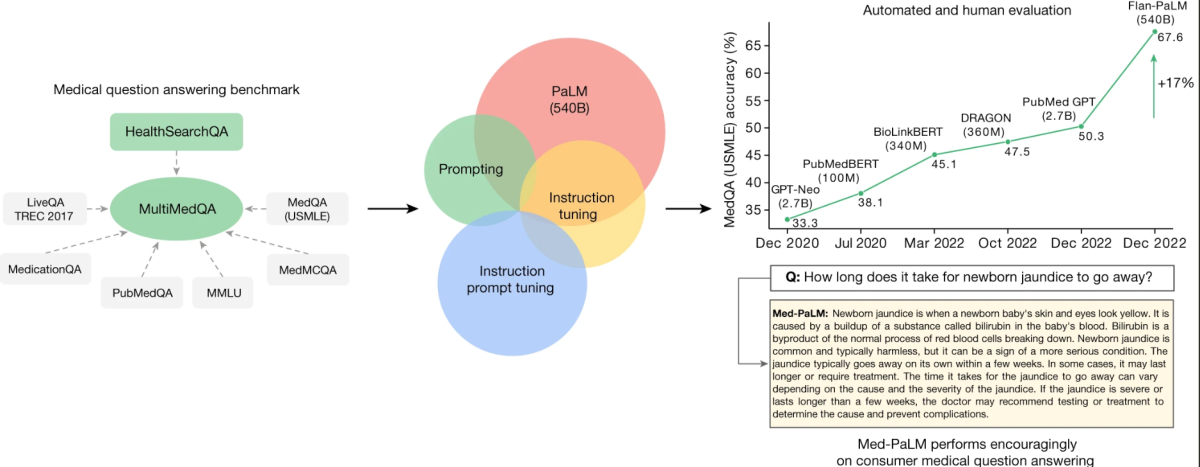
MultiMedQA, a benchmark for answering medical questions spanning medical examination
Key to the examine is the analysis of the Pathways Language Mannequin (PaLM), a 540-billion parameter LLM, and its instruction-tuned variant, Flan-PaLM, on the MultiMedQA. Remarkably, Flan-PaLM achieves state-of-the-art accuracy on all of the multiple-choice datasets inside MultiMedQA, together with a 67.6% accuracy on MedQA, which includes US Medical Licensing Examination-style questions. This efficiency marks a major enchancment over earlier fashions, surpassing the prior cutting-edge by greater than 17%.
MedQA
Format: query and reply (Q + A), a number of selection, open area.
Instance query: A 65-year-old man with hypertension involves the doctor for a routine well being upkeep examination. Present medicines embody atenolol, lisinopril, and atorvastatin. His pulse is 86 min−1, respirations are 18 min−1, and blood strain is 145/95 mmHg. Cardiac examination reveals finish diastolic murmur. Which of the next is the more than likely reason behind this bodily examination?
Solutions (right reply in daring): (A) Decreased compliance of the left ventricle, (B) Myxomatous degeneration of the mitral valve (C) Irritation of the pericardium (D) Dilation of the aortic root (E) Thickening of the mitral valve leaflets.
The examine additionally identifies vital gaps within the mannequin’s efficiency, particularly in answering client medical questions. To handle these points, the researchers introduce a way referred to as instruction immediate tuning. This method effectively aligns LLMs to new domains utilizing just a few exemplars, ensuing within the creation of Med-PaLM. The Med-PaLM mannequin, although it performs encouragingly and reveals enchancment in comprehension, data recall, and reasoning, nonetheless falls quick in comparison with clinicians.
A notable facet of this analysis is the detailed human analysis framework. This framework assesses the fashions’ solutions for settlement with scientific consensus and potential dangerous outcomes. For example, whereas solely 61.9% of Flan-PaLM’s long-form solutions aligned with scientific consensus, this determine rose to 92.6% for Med-PaLM, akin to clinician-generated solutions. Equally, the potential for dangerous outcomes was considerably lowered in Med-PaLM’s responses in comparison with Flan-PaLM.
The human analysis of Med-PaLM’s responses highlighted its proficiency in a number of areas, aligning intently with clinician-generated solutions. This underscores Med-PaLM’s potential as a supportive device in scientific settings.
The analysis mentioned above delves into the intricacies of enhancing Giant Language Fashions (LLMs) for medical purposes. The strategies and observations from this examine might be generalized to enhance LLM capabilities throughout numerous domains. Let’s discover these key facets:
Instruction Tuning Improves Efficiency
- Generalized Utility: Instruction tuning, which entails fine-tuning LLMs with particular directions or pointers, has proven to considerably enhance efficiency throughout numerous domains. This method might be utilized to different fields corresponding to authorized, monetary, or academic domains to boost the accuracy and relevance of LLM outputs.
Scaling Mannequin Dimension
- Broader Implications: The remark that scaling the mannequin measurement improves efficiency is just not restricted to medical query answering. Bigger fashions, with extra parameters, have the capability to course of and generate extra nuanced and sophisticated responses. This scaling might be useful in domains like customer support, inventive writing, and technical assist, the place nuanced understanding and response era are essential.
Chain of Thought (COT) Prompting
- Various Domains Utilization: The usage of COT prompting, though not at all times enhancing efficiency in medical datasets, might be useful in different domains the place advanced problem-solving is required. For example, in technical troubleshooting or advanced decision-making situations, COT prompting can information LLMs to course of data step-by-step, resulting in extra correct and reasoned outputs.
Self-Consistency for Enhanced Accuracy
- Wider Purposes: The strategy of self-consistency, the place a number of outputs are generated and essentially the most constant reply is chosen, can considerably improve efficiency in numerous fields. In domains like finance or authorized the place accuracy is paramount, this technique can be utilized to cross-verify the generated outputs for greater reliability.
Uncertainty and Selective Prediction
- Cross-Area Relevance: Speaking uncertainty estimates is essential in fields the place misinformation can have severe penalties, like healthcare and regulation. Utilizing LLMs’ potential to specific uncertainty and selectively defer predictions when confidence is low generally is a essential device in these domains to forestall the dissemination of inaccurate data.
The true-world software of those fashions extends past answering questions. They can be utilized for affected person training, helping in diagnostic processes, and even in coaching medical college students. Nevertheless, their deployment should be fastidiously managed to keep away from reliance on AI with out correct human oversight.
As medical data evolves, LLMs should additionally adapt and be taught. This requires mechanisms for steady studying and updating, guaranteeing that the fashions stay related and correct over time.

